
Building Trello with AngularJS and Neo4J
As I mentioned in one of the previous articles of this series, the project I am working on -- called Collaborative_Minds -- consists of implementing the basic functionalities of Trello, a free web-based project management application made by Fog Creek Software, the legendary New York based software development company founded by Joel Spolsky, the father of Stack Overflow.
Trello uses a paradigm for managing projects known as kanban:
- Projects are represented by a board
- each board contains a number of lists (corresponding to task lists)
- lists contain cards (corresponding to tasks).
Cards are supposed to progress from one list to the next, for instance mirroring the flow of a feature from idea to implementation.
Queue of queues of queues
Trello is a Single Page Application built with Backbone.js, Node.js and MongoDB -- you can read here all the details about Trello's cutting edge technology (as Joel himself describes it).
Maybe because I use Trello on a daily basis at work, I figured it would be the perfect candidate for an exercise to learn about SPAs, AngularJS, JavaScript-based programming stacks and Neo4J.
So, let's review one more time the basic idea of Trello:
- we have a number of Projects (represented as boards)
- every Project has a number of Lists (whose order can matter)
- every List contains a number of Cards (again the order could potentially matter)
I decided to implement this with a queue of queues of queues as the main data structure:
- a main queue of Projects
- each Project in the main queue has a queue of Lists
- each List contains a queue of Cards
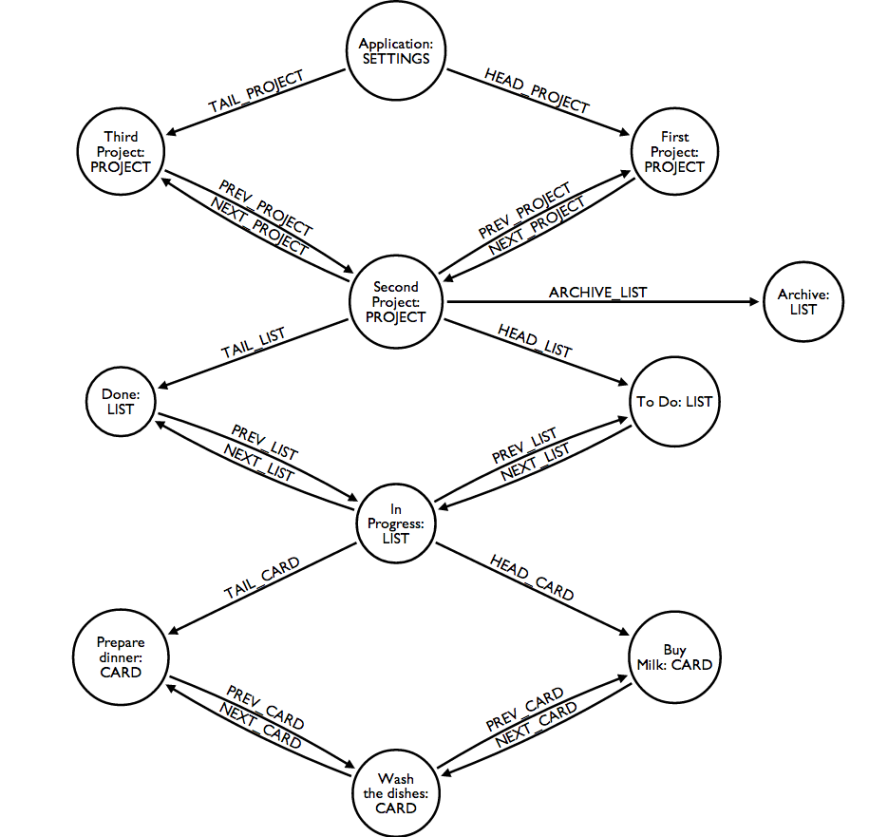
This structure is represented in the figure above as an oriented graph:
- the Application node contains a queue of projects (in the sample graph we see represented three projects)
- each queue is implemented with two relationships:
- HEAD_XYZ pointing to the head node of the queue
- TAIL_XYZ pointing to the tail node of the queue
- all nodes in the queue are linked together by two types of relationships:
- NEXT_XYZ pointing from the HEAD to the TAIL
- PREV_XYZ pointing from the TAIL to the HEAD
- each Project node contains a queue of lists (in the graph above, only "Second Project" has a queue of lists attached, with three lists, namely "To Do", "In Progress" and "Done")
- each Project node also has an Archive list, connected with the ARCHIVE_LIST relationship, which is used to store archived cards
- each List node contains a queue of cards (in the graph above, only the "In Progress" list has cards, three cards)
To represent an empty queue, for example when a List contains no cards, I adopted the convention where both the HEAD_CARD and the TAIL_CARD relationships point back to the list node itself.
Let's see what all this looks like when implemented in Neo4J. The following figure is a screenshot taken directly from the awesome Neo4J broswer. In this screenshot we can see a very basic structure, with 3 distinct projects, each with 3 lists and an archive list as well. No cards are present in this diagram.
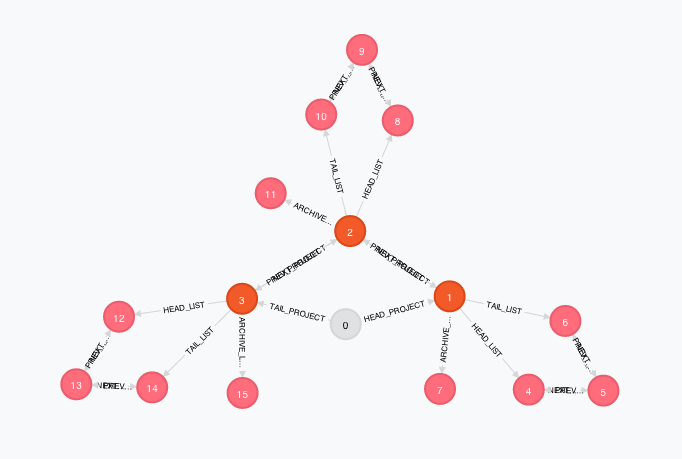
For reference, this is the cypher query that generates exactly the sample graph show above:
CREATE (mainApp:CollaborativeMinds { name: "Collaborative Minds" }),
(proj1:Project { name: "My First Project", company: "ABC Inc." }),
(proj2:Project { name: "My Second Project", company: "ACME" }),
(proj3:Project { name: "My Third Project", company: "XYZ Corp." }),
(mainApp)-[:HEAD_PROJECT]->(proj1), (mainApp)-[:TAIL_PROJECT]->(proj3),
(proj1)-[:NEXT_PROJECT]->(proj2), (proj2)-[:NEXT_PROJECT]->(proj3), (proj3)-[:PREV_PROJECT]->(proj2), (proj2)-[:PREV_PROJECT]->(proj1),
(proj1ToDoList:List { name: "To Do" }), (proj1InProgressList:List { name: "In Progress" }), (proj1DoneList:List { name: "Done" }), (proj1ArchiveList:List { name: "Archive" }),
(proj1)-[:ARCHIVE_LIST]->(proj1ArchiveList), (proj1)-[:HEAD_LIST]->(proj1ToDoList), (proj1)-[:TAIL_LIST]->(proj1DoneList),
(proj1ToDoList)-[:NEXT_LIST]->(proj1InProgressList), (proj1InProgressList)-[:NEXT_LIST]->(proj1DoneList), (proj1DoneList)-[:PREV_LIST]->(proj1InProgressList), (proj1InProgressList)-[:PREV_LIST]->(proj1ToDoList),
(proj1ArchiveList)-[:HEAD_CARD]->(proj1ArchiveList), (proj1ArchiveList)-[:TAIL_CARD]->(proj1ArchiveList),
(proj1ToDoList)-[:HEAD_CARD]->(proj1ToDoList), (proj1ToDoList)-[:TAIL_CARD]->(proj1ToDoList),
(proj1InProgressList)-[:HEAD_CARD]->(proj1InProgressList), (proj1InProgressList)-[:TAIL_CARD]->(proj1InProgressList),
(proj1DoneList)-[:HEAD_CARD]->(proj1DoneList), (proj1DoneList)-[:TAIL_CARD]->(proj1DoneList),
(proj2ToDoList:List { name: "To Do" }), (proj2InProgressList:List { name: "In Progress" }), (proj2DoneList:List { name: "Done" }), (proj2ArchiveList:List { name: "Archive" }),
(proj2)-[:ARCHIVE_LIST]->(proj2ArchiveList), (proj2)-[:HEAD_LIST]->(proj2ToDoList), (proj2)-[:TAIL_LIST]->(proj2DoneList),
(proj2ToDoList)-[:NEXT_LIST]->(proj2InProgressList), (proj2InProgressList)-[:NEXT_LIST]->(proj2DoneList), (proj2DoneList)-[:PREV_LIST]->(proj2InProgressList), (proj2InProgressList)-[:PREV_LIST]->(proj2ToDoList),
(proj2ArchiveList)-[:HEAD_CARD]->(proj2ArchiveList), (proj2ArchiveList)-[:TAIL_CARD]->(proj2ArchiveList),
(proj2ToDoList)-[:HEAD_CARD]->(proj2ToDoList), (proj2ToDoList)-[:TAIL_CARD]->(proj2ToDoList),
(proj2InProgressList)-[:HEAD_CARD]->(proj2InProgressList), (proj2InProgressList)-[:TAIL_CARD]->(proj2InProgressList),
(proj2DoneList)-[:HEAD_CARD]->(proj2DoneList), (proj2DoneList)-[:TAIL_CARD]->(proj2DoneList),
(proj3ToDoList:List { name: "To Do" }), (proj3InProgressList:List { name: "In Progress" }), (proj3DoneList:List { name: "Done" }), (proj3ArchiveList:List { name: "Archive" }),
(proj3)-[:ARCHIVE_LIST]->(proj3ArchiveList), (proj3)-[:HEAD_LIST]->(proj3ToDoList), (proj3)-[:TAIL_LIST]->(proj3DoneList),
(proj3ToDoList)-[:NEXT_LIST]->(proj3InProgressList), (proj3InProgressList)-[:NEXT_LIST]->(proj3DoneList), (proj3DoneList)-[:PREV_LIST]->(proj3InProgressList), (proj3InProgressList)-[:PREV_LIST]->(proj3ToDoList),
(proj3ArchiveList)-[:HEAD_CARD]->(proj3ArchiveList), (proj3ArchiveList)-[:TAIL_CARD]->(proj3ArchiveList),
(proj3ToDoList)-[:HEAD_CARD]->(proj3ToDoList), (proj3ToDoList)-[:TAIL_CARD]->(proj3ToDoList),
(proj3InProgressList)-[:HEAD_CARD]->(proj3InProgressList), (proj3InProgressList)-[:TAIL_CARD]->(proj3InProgressList),
(proj3DoneList)-[:HEAD_CARD]->(proj3DoneList), (proj3DoneList)-[:TAIL_CARD]->(proj3DoneList)
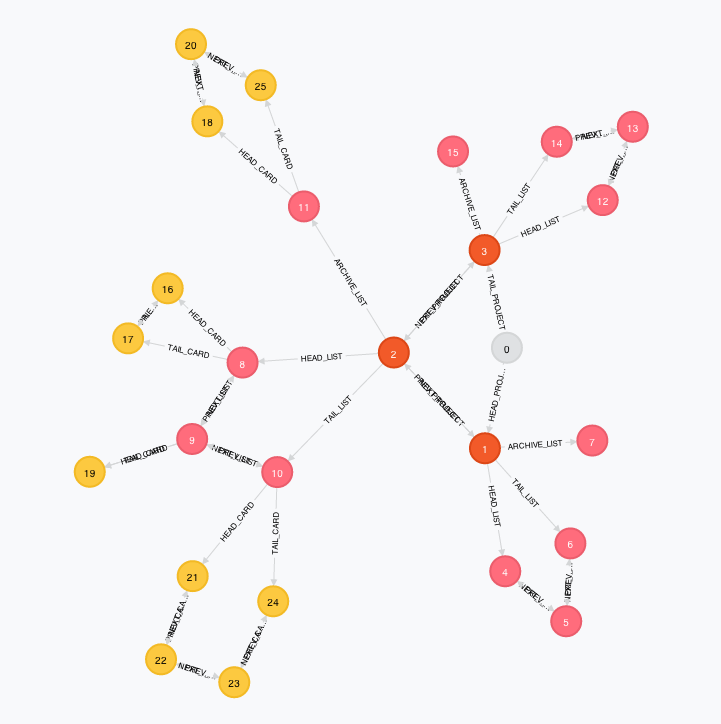
In the next figure, I have added a few cards to each of the lists of the second project. I have archived a few cards as well, to show what the archive looks like:
Once settled for the above data structure, I immediately started working on building the two main queries I needed to be able to insert new cards and to archive existing ones.
Inserting a New Card
Being these queues, all cards need to be inserted at the end of the queue, in other words at the tail of the queue, keeping in mind that an empty queue is represented by both the head and the tail relationships pointing back to the empty list node. This means that we have two cases:
- when the list is initially empty, inserting the first card means changing the HEAD_CARD and the TAIL_CARD relationships to be both pointing at the first card
- when the list has already at least one card, in other words when the list already has a tail, we need to change the TAIL_CARD relationship to point to the new card, and then build:
- a PREV_CARD relationship going from the new card to the previous tail
- a NEXT_CARD relationship going from the previous tail to the new card
Using the power of the OPTIONAL MATCH, I translated this idea in the following query:
// first get a hold of the list to which we want to add the new card
MATCH (theList:List) WHERE ID(theList)=5
// check if the list already has at least one card
OPTIONAL MATCH (theList)-[tlct:TAIL_CARD]->(currentTail:Card)
// check if the list is empty
OPTIONAL MATCH (theList)-[tltl1:TAIL_CARD]->(theList)-[tltl2:HEAD_CARD]->(theList)
WITH
theList,
CASE WHEN currentTail IS NULL THEN [] ELSE [(currentTail)] END AS currentTails,
currentTail, tlct,
CASE WHEN tltl1 IS NULL THEN [] ELSE [(theList)] END AS emptyLists,
tltl1, tltl2
// create the new card
CREATE (newCard:Card { title: "Card Title", description: "" })
// handle the case in which the list already had at least one card
FOREACH (value IN currentTails |
CREATE (theList)-[:TAIL_CARD]->(newCard)
CREATE (newCard)-[:PREV_CARD]->(currentTail)
CREATE (currentTail)-[:NEXT_CARD]->(newCard)
DELETE tlct)
// handle the case in which the list was empty
FOREACH (value IN emptyLists |
CREATE (theList)-[:TAIL_CARD]->(newCard)
CREATE (theList)-[:HEAD_CARD]->(newCard)
DELETE tltl1, tltl2)
RETURN newCard
Not too bad… Although I have to admit that it took me a while to get to this query in the form you see it here, being that I am not familiar with cypher and graph databases.
Essentially, OPTIONAL MATCH statements identify which scenario are we in, either working with an empty list or with a list that has already some cards in it.
Then, each of those CASE statements generate either an empty array or an array with exactly one element. These arrays are then being used as logical switches by the FOREACH statements that drive the logic underneath each case.
Archiving a Card
Let's take a look again at the simple graph I introduced earlier that shows a few cards loaded into three lists:
Now imagine the process of taking anyone of those cards and moving it into the archive queue. It shouldn't be too hard to see that we can have 4 different scenarios:
- The card to be archived is the only card in that list (see card #19 in the graph above). In this case we need to move the card and then, based on the convention we adopted, point the HEAD_CARD and TAIL_CARD relationships back to the list node.
- The card is in the middle of a queue (see cards #22 and #23 in the graph above). This is the simplest case. Simply move the card, delete all its relationships with the card before and after, and finally link the card before and the card after with both a NEXT_CARD and a PREV_CARD relationships.
- The card is at the head of a queue (such as cards #16 and #21 in the graph above). In this case we need to move the card to the archive, delete all its relationships with both the list node and the card immediately next in the queue. Finally we need to create a new HEAD_CARD relationship going from the list node to the new head of the queue.
- Symmetric case to #3. The card is at the tail of a queue (such as cards #17 and #24 in the graph above). In this case we need to move the card to the archive, delete all its relationships with both the list node and the card immediately previous in the queue. Finally we need to create a new TAIL_CARD relationship going from the list node to the new tail of the queue.
If you have understood well how the insertion query works, you should be able to grasp the following query as well:
// first let's get a hold of the card we want to archive
MATCH (theCard:Card) WHERE ID(theCard)=44
// next, let's get a hold of the correspondent archive list node, since we need to move the card in that list
OPTIONAL MATCH (theCard)<-[:NEXT_CARD|HEAD_CARD*]-(theList:List)(theArchive:List)
// let's check if we are in the case where the card to be archived is in the middle of a list
OPTIONAL MATCH (before:Card)-[btc:NEXT_CARD]->(theCard:Card)-[tca:NEXT_CARD]->(after:Card)
OPTIONAL MATCH (next:Card)-[ntc:PREV_CARD]->(theCard:Card)-[tcp:PREV_CARD]->(previous:Card)
// let's check if the card to be archived is the only card in the list
OPTIONAL MATCH (listOfOne:List)-[lootc:TAIL_CARD]->(theCard:Card)(theCard:Card)-[tcs:NEXT_CARD]->(second:Card)-[stc:PREV_CARD]->(theCard:Card)
// let's check if the card to be archived is at the tail of the list
OPTIONAL MATCH (listToTail:List)-[ltttc:TAIL_CARD]->(theCard:Card)-[tcntl:PREV_CARD]->(nextToLast:Card)-[ntltc:NEXT_CARD]->(theCard:Card)
WITH
theCard, theList, theProject, theArchive,
CASE WHEN theArchive IS NULL THEN [] ELSE [(theArchive)] END AS archives,
CASE WHEN before IS NULL THEN [] ELSE [(before)] END AS befores,
before, btc, tca, after,
CASE WHEN next IS NULL THEN [] ELSE [(next)] END AS nexts,
next, ntc, tcp, previous,
CASE WHEN listOfOne IS NULL THEN [] ELSE [(listOfOne)] END AS listsOfOne,
listOfOne, lootc, tcloo,
CASE WHEN listToHead IS NULL THEN [] ELSE [(listToHead)] END AS listsToHead,
listToHead, lthtc, tcs, second, stc,
CASE WHEN listToTail IS NULL THEN [] ELSE [(listToTail)] END AS listsToTail,
listToTail, ltttc, tcntl, nextToLast, ntltc
// let's handle the case in which the archived card was in the middle of a list
FOREACH (value IN befores |
CREATE (before)-[:NEXT_CARD]->(after)
CREATE (after)-[:PREV_CARD]->(before)
DELETE btc, tca)
FOREACH (value IN nexts | DELETE ntc, tcp)
// let's handle the case in which the archived card was the one and only card in the list
FOREACH (value IN listsOfOne |
CREATE (listOfOne)-[:HEAD_CARD]->(listOfOne)
CREATE (listOfOne)-[:TAIL_CARD]->(listOfOne)
DELETE lootc, tcloo)
// let's handle the case in which the archived card was at the head of the list
FOREACH (value IN listsToHead |
CREATE (listToHead)-[:HEAD_CARD]->(second)
DELETE lthtc, tcs, stc)
// let's handle the case in which the archived card was at the tail of the list
FOREACH (value IN listsToTail |
CREATE (listToTail)-[:TAIL_CARD]->(nextToLast)
DELETE ltttc, tcntl, ntltc)
// finally, let's move the card in the archive
// first get a hold of the archive list to which we want to add the card
WITH
theCard,
theArchive
// first get a hold of the list to which we want to add the new card
OPTIONAL MATCH (theArchive)-[tact:TAIL_CARD]->(currentTail:Card)
// check if the list is empty
OPTIONAL MATCH (theArchive)-[tata1:TAIL_CARD]->(theArchive)-[tata2:HEAD_CARD]->(theArchive)
WITH
theArchive, theCard,
CASE WHEN currentTail IS NULL THEN [] ELSE [(currentTail)] END AS currentTails,
currentTail, tact,
CASE WHEN tata1 IS NULL THEN [] ELSE [(theArchive)] END AS emptyLists,
tata1, tata2
// handle the case in which the list already had at least one card
FOREACH (value IN currentTails |
CREATE (theArchive)-[:TAIL_CARD]->(theCard)
CREATE (theCard)-[:PREV_CARD]->(currentTail)
CREATE (currentTail)-[:NEXT_CARD]->(theCard)
DELETE tact)
// handle the case in which the list was empty
FOREACH (value IN emptyLists |
CREATE (theArchive)-[:TAIL_CARD]->(theCard)
CREATE (theArchive)-[:HEAD_CARD]->(theCard)
DELETE tata1, tata2)
RETURN theCard
Nonetheless, this is a massive query. I am not sure about its performance, because I haven't measured it, but its relative complexity is already enough to make me think that there must be a way to simplify this, possibly modifying the underlying data structure.
Furthermore, keep in mind, that it took me a long time to come up with this query. What inspired me to build this query the way I did, was a clever graph gist to play Tic Tac Toe using cypher queries posted by @SylvainRoussy. Before getting this inspiration I was stuck at running four separate queries, which is when I decided to ask for help on Stack Overflow.
A few days after posting my question, Graph Grandmaster Wes Freeman left an eye-opening comment:
You might be interested to see my skip list graph gist… it handles empty lists by having a tail and head that are never deleted, so the case is always the same (removing an internal node)
This is brilliant. Not just because it reveals a much easier way to solve the problem at hand, but because it was a real eye opener for me. When I think of data structures, in my head I visualize them the way I was used to do it in college, like in the following figure, which is taken from Wikipedia and shows a doubly-linked list:

This automatically translated in my head into the need for a graph relationship every time I saw a pointer in the data structure. Wes' comment made me finally realize that a node is an even better translation, especially when it allows to simplify the number of scenarios when working with the data structure itself.
And so we are back to the drawing board. The results will come in the next post of this series.